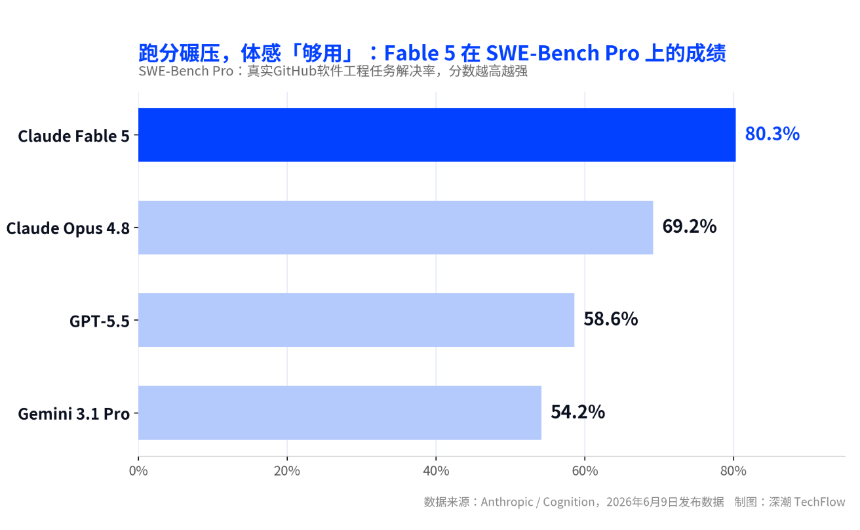
Anthropic公司于6月9日发布了新一代Claude Fable 5模型,该模型在真实软件工程任务基准SWE-Bench Pro上取得了80.3%的分数,领先于其前代旗舰Opus 4.8及竞争对手GPT-5.5。然而,这份纸面成绩单并未完全转化为用户口碑。发布三天后,一篇题为「Claude Fable让我意识到,我不需要更好的模型了」的帖子在Reddit的r/artificial版块成为热帖,引发了广泛讨论。
帖子发帖人Axi0m-22分享了自己的使用体验:在尝试用Fable 5进行安全研究和日常工作后,他很快切换回了Opus处理代码任务,用更轻量的Haiku模型处理杂活。他将此比喻为手持iPhone 14观看iPhone 17发布会——明知新款更好,但觉得手头的设备已足够好用。这一观点在评论区引发了大量共鸣。
高赞评论普遍表达了「够用主义」的情绪。排名第一的评论指出,除了更大的上下文窗口,自Opus 4.5之后便不再感觉迫切需要更强的模型。用户hyprlab则表示,换用一个消耗token更快的模型并未给其工作流带来明显好处,Opus 4.8的高强度模式已足够舒适。背后是清晰的成本考量:Fable 5的API定价为每百万输入token 10美元,接近Opus 4.8的两倍。用户siromega37直言,更高的token消耗没有带来相应的投资回报,并认为行业可能正面临平台期。
除了成本,安全护栏成为用户最大的抱怨点。Anthropic官方说明,Fable 5与仅限机构使用的Mythos 5共享底层模型,但为公众版本加装了安全分类器,会拦截涉及网络安全等高风险的请求,并转由Opus 4.8代为回答。官方称触发率低于5%,但用户体感远高于此。用户jradoff抱怨,只要提及安全相关事宜,Fable 5基本都会拒绝处理。另一条评论更是尖锐地指出:「你想用它干的事90%都会被拒,等于没用。」付费用户的不满更为强烈,有订阅200美元档位的用户表示,支付双倍费用却在进行安全审查时被降级到Opus,体验糟糕。
然而,反对声音同样存在,且多来自重度任务用户。用户Phylaras表示,Fable 5在处理对上下文窗口要求极高的复杂任务时,发现了以往未曾察觉的错误。一位从事高能物理仿真的用户提到,仿真项目常涉及上万行代码和数百个模型的交互,一个能独立连续工作、理解环境细节的模型极具价值。用户Navetz的评论更为激烈,他认为用过Fable 5的人会觉得「不需要更好模型」的帖子是疯话,并将其能力提升比喻为从大学生球员直接晋级为NBA首发。
也有用户提出了折中使用策略,建议将Fable 5作为「规划者和修复者」用于关键环节,而非日常的「建造者」,以控制成本。一条评论总结道:用Fable 5处理简单表格是选错了模型,用轻量模型Haiku运行复杂多智能体任务同样是选错了模型,关键在于匹配场景。
这场争论延伸至对行业结构的思考。用户KedMcJenna提出了「公开AI冻结论」,猜测公众能接触到的模型能力可能将长期徘徊在当前水平,而更强的私有模型(如Mythos 5)将持续提供给企业和政府精英。这指向一个现实:Mythos 5目前仅通过Project Glasswing计划提供给特定机构。
基准测试的高分与用户社区的冷淡反应并不矛盾。前者衡量能力上限,后者反映日常需求天花板。当多数用户的任务已被现有模型满足,更强大的模型只能在极端专业场景中证明其价值。对模型厂商而言,挑战已从「能否做到」转变为「谁需要、愿付多少代价、能容忍多少安全摩擦」。Fable 5发布三天,收获了两份截然不同的成绩单。其最终市场表现,将取决于Anthropic对安全策略的调整速度,以及重度专业用户的付费意愿。