大多数人都知道小米是中国手机品牌。生产廉价电动滑板车和空气净化器的公司。这家公司并不完全是您所期望的在周一早上打破主要人工智能推理速度记录的公司。
然而。小米刚刚发布了 MiMo-V2.5-Pro-UltraSpeed,这是一种针对其万亿参数旗舰产品的服务模式,每秒可处理超过 1,000 个令牌,在演示中峰值接近 1,200 个。
参数是定义模型如何思考的内部数字权重 - 参数越多,它可以识别的模式就越复杂。标记是模型读取和写入的文本块,平均每个文本块大约是一个单词的四分之三。
小米在单个 8-GPU 商品节点上做到了这一点。标准硬件,无定制芯片。这改变了谁可以在生产中实际部署这种速度的计算方式。
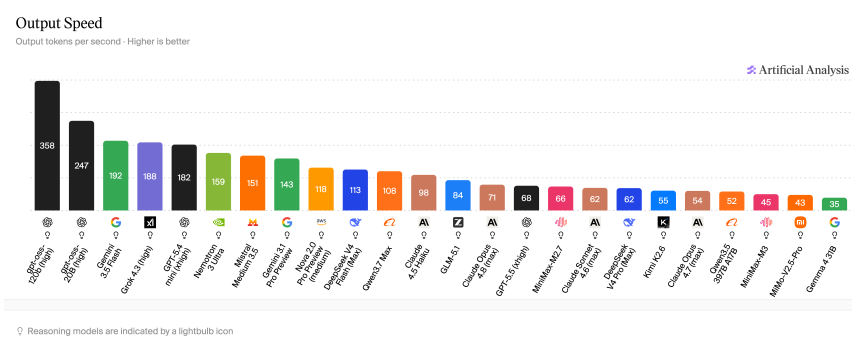
用人类的术语来说:根据人工分析,GPT-5.5(大多数 ChatGPT 用户实际上正在谈论的内容)为 68。Claude Opus 4.6 的得分约为 71,而低端模型 Haiku 则每秒达到 98 个令牌。 Gemini Flash 每秒可处理 192 个令牌。 MiMo-V2.5-Pro-UltraSpeed 在编码基准测试中与 Opus 相匹配的模型上执行了 1,000 次。
Cerebras 和 Groq 围绕这个问题建立了整个业务。 Cerebras 设计了一款餐盘大小的晶圆级芯片,配备 44GB 片上内存,以消除减慢 GPU 推理速度的带宽瓶颈。它在 Meta 的 Llama 3.1 405B 上达到了每秒 969 个令牌,令人印象深刻,但这是一个 4050 亿参数的模型,不到 MiMo-V2.5-Pro 大小的一半。 Groq 的自定义语言处理单元架构每秒最多可处理 300–750 个令牌,具体取决于型号。
两者都无法在您今晚可以从 AWS 租用的硬件上运行。
小米仅通过软件在商用 GPU 上做到了这一点——结合了模型级技巧和名为 TileRT 的专用推理引擎。
幕后实际发生了什么
两种技术可以提高速度。第一种技术称为 FP4 量化:小米不是以完整的 8 位或 16 位数值精度运行模型,而是将专家层(构成 1 万亿个参数的大部分)缩小到 4 位。内存占用下降,带宽压力下降,速度提高。捕获的结果通常是轻微的质量下降。小米的解决方案是外科手术:只有专家层被压缩,其他所有内容都保持完全精确。通过这种方法,质量损失被描述为接近于零。
第二个是 DFlash 推测解码。正常的推测解码有一个小草稿模型猜测接下来的几个标记,然后大模型并行验证它们。 DFlash 完全跳过了顺序起草——它在一次前向传递中填充了整个屏蔽位置块。在编码任务中,大模型在每轮验证中平均接受 8 个提议令牌中的 6.3 个。一步确认了六个令牌,而不是一个。
TileRT 将其联系在一起。它使整个计算管道持续驻留在 GPU 内 - 没有每个操作员的启动开销,没有执行间隙。
小米将这种方法称为“极限模型系统协同设计”,这句话是准确的:单独使用两种技术都无法达到每秒 1,000 个令牌,但所有方法之间的协同作用却可以达到每秒 1,000 个令牌。
MiMo-V2.5-Pro是一款前沿型号。我们报道了 4 月份发布的 V2.5 Pro——它在大多数编码基准上与 Claude Opus 相匹配,并且每百万代币的运行成本约为 0.43 美元输入/0.87 美元输出。每百万代币 Opus 的投入成本为 5 美元/产出成本为 25 美元。
UltraSpeed 加速了确切的 MiMo V2.5 Pro 模型,而不是精简版本。
足够快的推理会改变您使用模型的方式。您可以并行运行数十条推理路径,而不是等待一个答案。欺诈检测、交易信号生成、实时代理循环——所有这些都具有每秒 60 个代币无法满足的硬延迟限制。以每秒 1,000 个令牌的速度,他们可以。
小米的定价是标准 MiMo-V2.5-Pro 速率的 3 倍,输出功率约为 10 倍。 API 试用期为 6 月 9 日至 23 日,基于应用程序,优先考虑企业和专业开发人员。 FP4-DFlash 检查点已在 Hugging Face 上开源以进行社区测试。